collection集合
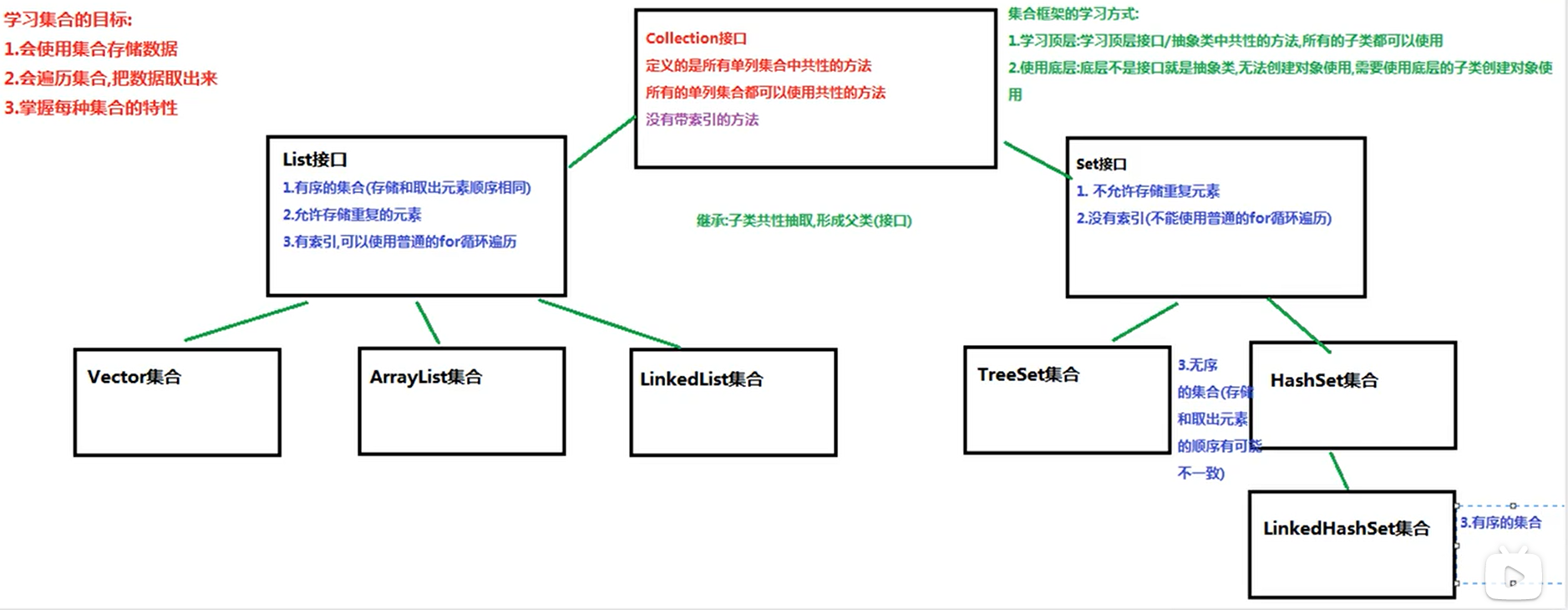
集合是存储数据的框架,只能用来存放对象元素,collection集合是最顶层的父类接口,其有2个子接口List和Set,分别代表着两类不同的集合,List接口实现的集合是有序的集合,有索引,元素可以重复;而Set接口实现的集合没有索引,并且不允许存放相同的元素,关于集合的体系结构如下图所示:
colletion <String> coll = new ArrayList<>();- collection集合定义了一些常用的公共的方法如下:
1
2
3
4
5
6
7boolean add(E e); //向集合添加数据
boolean remove(E e); //删除集合中的元素
void clear(); //清空集合
boolean contains(E e); //判断是否含有某个元素
boolean isEmpty(); //判断集合是否为空
int size(); //获取集合的长度
Object[] toArray(); //将集合转换成数组
迭代器Iterator
因为不同集合存储的数据类型可能不一样,所以对集合的存取元素的操作方法也不一样,为了方便统一,我们可以使用Iterator迭代器,它有着对集合的通用操作方法
因为Iterator是一个接口,我们不能直接使用它,所以我们一般通过多态,先建立一个集合对象,然后通过集合对象来实现Iterator接口,建立一个对集合对象的迭代器:
Collection
coll = new LinkedList<>();
Iteratorit = coll.iterator(); Iterator也有泛型,但是它必须和调用它的对象的泛型一致,所以Iterator的泛型可以省略不写,但是写上的话必须和集合对象保持一致
Iterator的常用方法
1.boolean hasNext();
这个方法用于判断集合中是否还有元素,有的话就返回true,使用方法如下:Collection
coll = new LinkedList<>();
coll.add(“a”);
coll.add(“b”);
Iterator it = coll.iterator();
boolean b = it.hasNext(); //b=true
2.E next();
这个方法用于取出集合的第一个元素,使用方法如下:
Collection<String> coll = new LinkedList<>();
coll.add("a");
coll.add("b");
Iterator it = coll.iterator();
String s = it.next(); //s="a"这两个方法都是重复的,所以我们一般是搭配循环来使用:
while(it.hasNext())
{
System.out.println(it.next());
}- iterator迭代器的原理:其实iterator就像一个指针,当创建集合的迭代器时,iterator指针会指向集合索引的-1位置,hasNext就是判断指针下一位是否存在元素,next方法就是将指针移向下一位,并获取指针指向的元素。所以iterator的操作并不会对集合本身产生影响
增强for循环
增强for循环时专门用来遍历数组和集合的,其使用方法如下:
1 | //遍历数组 |
泛型
当我们不知道使用什么数据类型时,就可以使用泛型
- 含有泛型的类
定义含有泛型的类,可以方便我们不知道类的成员的类型的情况,其结构如下:在创建含有泛型的类的对象时,如果没有对泛型进行定义,那么默认为Object类型1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class GenericClass<E> {
E name;
int age;
public void setName(E name) {
this.name = name;
}
public E getName() {
return name;
}
public static void main(String[] args) {
GenericClass <String> gc = new GenericClass<>();
gc.setName("Tonm");
System.out.println(gc.getName());
}
} - 含有泛型的方法
在含有泛型的方法时,调用它时传递的参数是什么类型,泛型就时什么类型,如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public class GenericClass<E> {
E name;
int age;
public void setName(E name) {
this.name = name;
}
public E getName() {
return name;
}
public <M> void typeOfM(M m) {
System.out.println(m);
}
public static void main(String[] args) {
GenericClass <String> gc = new GenericClass<>();
gc.typeOfM(1); //M为Interger类型
gc.typeOfM("string"); //M为String类型
}
} - 含有泛型的接口
含有泛型的接口定义有两种方式:
1.在实现接口的类时定义接口的泛型
1 | //含有泛型的接口定义 |
2.在创建泛型实现类的对象时定义泛型
1 | public class GenericInterfaceImpl<I> implements GenericInterface<I>{ |
- 泛型通配符
当使用一个方法时的参数类型不确定时,可以使用泛型通配符?,可以接受任意类型的泛型,如下:使用类型通配符的好处呢就是,当定义一个方法时需要使用多次,并且每次使用时的类型都不一样,这时候就可以使用类型通配符1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import java.util.ArrayList;
public class GenericClass {
public void printArray(ArrayList<?> array){
System.out.println(array);
}
public static void main(String[] args) {
GenericClass <String> gc = new GenericClass<>();
ArrayList <String> array1 = new ArrayList<>();
array1.add("str1");
array1.add("arr2");
ArrayList <Integer> array2 = new ArrayList<>();
array2.add(1);
array2.add(2);
gc.printArray(array1);
gc.printArray(array2);
}
}
LinkedList集合
linkedList集合不同于ArrayList集合之处就在于ArrayList集合底层用数组实现,而LinkedList底层是用链表实现的,相比于ArrayList增删快,查找慢。LinkedList不建议使用多态进行创建,因为使用多态子类的特殊方法就无法使用,LinkedList的一些常用的特有方法如下:
- addFirst(E e); addFirst方法就是在List的最前面插入一个元素,其作用等同于List的push方法
- addLast(E e); addLast方法就是在List的最后面插入一个元素,其作用等同于add方法
- getFirst(); getFirst方法就是获取List的最前面的一个元素
- getLast(); getLst方法就是获取List最后面的一个元素
- removeFirst(); removeFirst方法就是删除List最前面的一个元素,等同于pop方法
- removeLast(); removeLst方法就是删除List最后面的一个元素
HashSet集合
HashSet集合实现了Set接口,其底层使用哈希表实现,优点是访问速度非常快,它有着和set集合一样的特点如下:

1 | Set <String> set = new HashSet<>(); |
1 | //iterator迭代器遍历 |
1 | public String toString() { |
1 | String s1 = new String("abc"); |
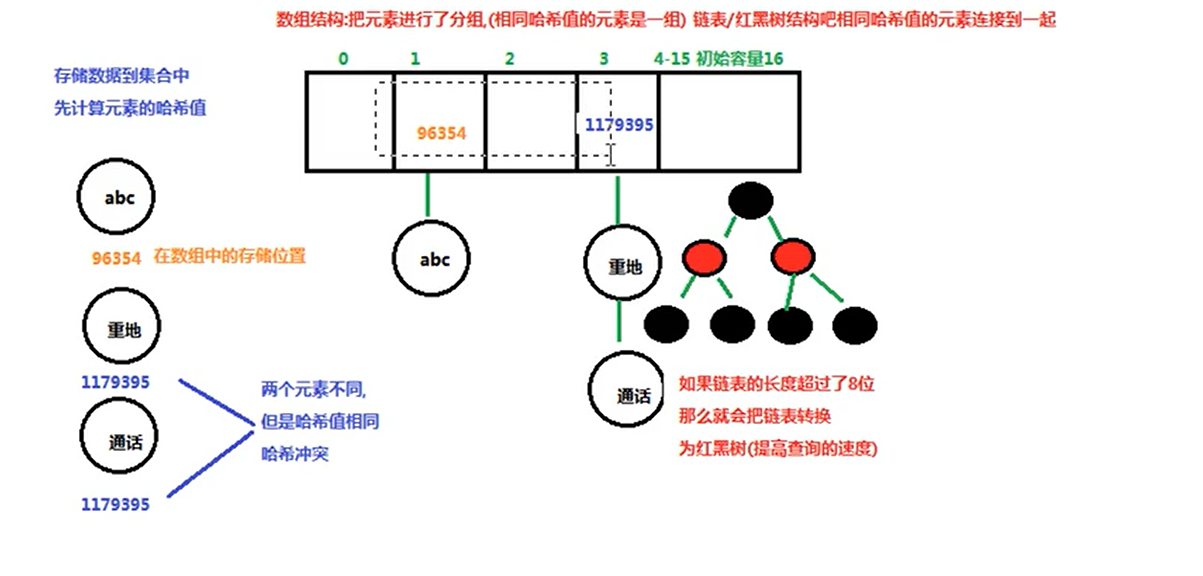
Set集合不能存放相同数据的原因
在Set集合中,调用add方法的同时会调用hashCode方法和equals方法,首先会对将要插入集合的对象调用hashcode方法获取其哈希值,然后调用equals方法将其与集合中的元素依次进行比较,如果都不相同,则将该元素放入集合中,相同则不进行放入操作
Collections工具类
Collections工具类是对集合操作的一个工具类,其中具有很多操作集合的方法
- Collections.addAll(list,element…);
addAll方法可以一次性向集合中添加多个元素:1
2
3ArrayList <String> arraylist = new ArrayList<>();
Collections.addAll(arraylist,"a","b","c");
System.out.println(arraylist); //[a,b,c] - Collections.shuffle(list);
shuffle方法可以将集合中的元素打乱:1
2
3
4
5ArrayList <String> arraylist = new ArrayList<>();
Collections.addAll(arraylist,"a","b","c");
System.out.println(arraylist); //[a,b,c]
Collections.shuffle(arraylist);
System.out.println(arraylist); //[b,c,a] - Collections.sort(list);
sort方法可以对集合中的元素进行排序,注意sort方法只可以对实现了comparable接口的类的集合使用:1
2
3
4
5
6
7
8
9
10
11ArrayList<Integer> list1 = new ArrayList<>();
Collections.addAll(list1,1,3,2,4);
System.out.println(list1); //[1,3,2,4]
Collections.sort(list1);
System.out.println(list1); //[1,2,3,4]
ArrayList<String> list2 = new ArrayList<>();
Collections.addAll(list2,"a","c","d","b");
System.out.println(list2); //[a,c,d,b]
Collections.sort(list2);
System.out.println(list2); //[a,b,c,d]
Map集合
- map集合在java.util.Map包下,用于保存具有映射关系的数据,是一个双列集合,一个元素包括两个值:key和value.
1.map集合中的元素key和value的类型可以相同,也可以不同
2.map集合中的元素key不可以重复,但是value可以重复
3.map集合中的元素key和value一一对应
- HashMap底层以哈希表实现,查询速度快,但是存储的元素无序
- LinkedHashMap底层以哈希表和链表实现,是有序的集合
Map中的一些方法
- put(k,v);
put方法用于向集合中添加元素,输出将会以{k1=v1,k2=v2}的形式输出,同时put方法也有返回值,会返回key的value:1
2
3
4
5
6
7
8Map <String,String> map = new HashMap<>();
map.put("p1","p2");
String v1 = map.put("q1","q2");
System.out.println(v1); //null
System.out.println(map); //{q1=q2, p1=p2}
String v2 = map.put("p1","p3");
System.out.println(v2); //q2
System.out.println(map); //{q1=q2, p1=p3} - remove(k);
remove方法可以删除map集合中key为k的元素,并返回对应的value,如果没有则返回null1
2
3String s = map.remove("p1");
System.out.println(s); //p3
System.out.println(map); //{q1=q2} - get(k);
get方法用于查找map集合中key为k的value值并返回,没有则返回null1
2String v = map.get("q1");
System.out.println(v); //q3 - containKey(k);
containKey用于查找map集合中是否含有key为k的元素:1
2
3
4Boolean b1 = map.containsKey("q1");
Boolean b2 = map.containsKey("p1");
System.out.println(b1); //true
System.out.println(b2); //falseMap的遍历
- 使用KeySet方法将Map的key放置到set集合中,再通过getKey方法获取value
1
2
3
4
5
6
7
8
9
10
11Map <String,String> map1 = new HashMap<>();
map1.put("k1","v1");
map1.put("k2","v2");
map1.put("k3","v3");
Set <String> set = map1.keySet();
Iterator<String> it = set.iterator();
while(it.hasNext()){
String key = it.next();
System.out.println(map1.get(key));
}
//v1,v2,v3使用map获取字符串的字符出现次数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import java.util.Scanner;
import java.util.HashMap;
public class numOfCharInString {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String str = sc.next();
System.out.println(str);
HashMap <Character,Integer> map = new HashMap<Character, Integer>();
for(char ch : str.toCharArray()){
if(map.containsKey(ch)){
Integer value = map.get(ch);
value++;
map.put(ch,value);
}else{
map.put(ch,1);
}
}
for(Character c : map.keySet()){
System.out.println(c+":"+map.get(c));
}
}
}





