数据预处理 数据处理可谓是机器学习的重中之重,接下来我所用到的数据集和代码如下:数据集 ,代码
导入库 首先需要导入python库函数:
1 2 3 4 5 6 7 8 9 10 import numpy as npimport pandas as pdfrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import LabelEncoder, OneHotEncoderfrom sklearn.compose import ColumnTransformerfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler
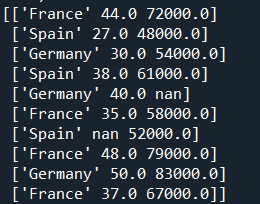
导入数据集 原本的数据集为:
然后开始经过以下处理:
1 2 3 dataset = pd.read_csv('Data.csv' ) X = dataset.iloc[ : , : -1 ].values Y = dataset.iloc[ : , 3 ].values
其中X为:
Y为:
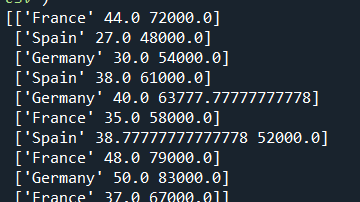
处理丢失数据 很多时候,我们得到的数据集中会有数据丢失的部分,通过以下处理,在丢失数据的部分给与平均值
1 2 3 imputer = SimpleImputer(missing_values = np.nan, strategy = "mean" ) imputer = imputer.fit(X[ : , 1 :3 ]) X[ : , 1 :3 ] = imputer.transform(X[ : , 1 :3 ])
处理后的X如下,我们可以发现空白的部分被填上了平均值:
数据分类 将数据集中的数据进行分类,相同的数字代表同一类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 labelencoder_X = LabelEncoder() labelencoder_Y = LabelEncoder() X[ : , 0 ] = labelencoder_X.fit_transform(X[ : , 0 ]) ct1 = ColumnTransformer([("country" , OneHotEncoder() , [1 ])], 'drop' ) ct2 = ColumnTransformer([("country" , OneHotEncoder() , [1 ])], 'drop' ) X = ct1.fit_transform(X).toarray() Y = labelencoder_Y.fit_transform(Y) ``` 处理后的X如下,我们可以发现数据集都变成了数字,其中相同的类别数字相同: <div aligh=center><img src="https://cdn.jsdelivr.net/gh/sunyuzero/cdn/py/c5.png" width=200></div> 用train_test_split拆分数据集,其中test_size表示测试集所占数据集的比例 ```python X_train , X_test , Y_train , Y_test = train_test_split( X , Y , test_size = 0.2 , random_state = 0 )
处理后的X_train(训练集)如下,占80%:
X_test(数据集)如下,占20%:
特征量化 用特征标准化或Z值归一化实现特征量化,解决其他模型算法的特征在幅度,单位和范围姿态问题上变化很大的问题
1 2 3 sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test)